是一類機器學習演算法,其目的在於從未標記的資料中找出潛在的結構、模式或關係。與監督式學習不同,非監督式學習不需要事先提供正確答案,而是讓演算法自行探索資料中的隱藏資訊
聚類分析(Clustering):將資料分為數個群組,使同一個群組內的資料相似度高,不同群組之間的資料相似度低
K-Means Clustering:隨機選取K個初始中心點,將每個資料點分配到最近的中心點,並重新計算中心點,重複此過程直到中心點不再變化DBSCAN:根據資料點密度將資料分群,能發現任意形狀群組Hierarchical Clustering:將資料點逐層合併或分裂,形成樹狀結構降維(Dimensionality Reduction):將高維度的資料轉換為低維度的表示,同時保留原資料主要資訊
PCA(Principal Component Analysis):找到資料變異量最大的方向,將資料投影到這些方向上t-SNE:將高維資料映射到低維空間,同時保留資料的局部和全局結構異常檢測(Anomaly Detection):找出與大多數資料點顯著不同資料點
Isolation Forest:將資料點隨機切割,計算資料點被隔離所需切割的次數,異常點通常需要較少的切割次數DBSCAN核心點:在半徑 ε 內至少包含 min_samples 個點邊界點:在半徑 ε 內包含少於 min_samples 個點,但屬於其他核心點的鄰域噪聲點:既不是核心點也不是邊界點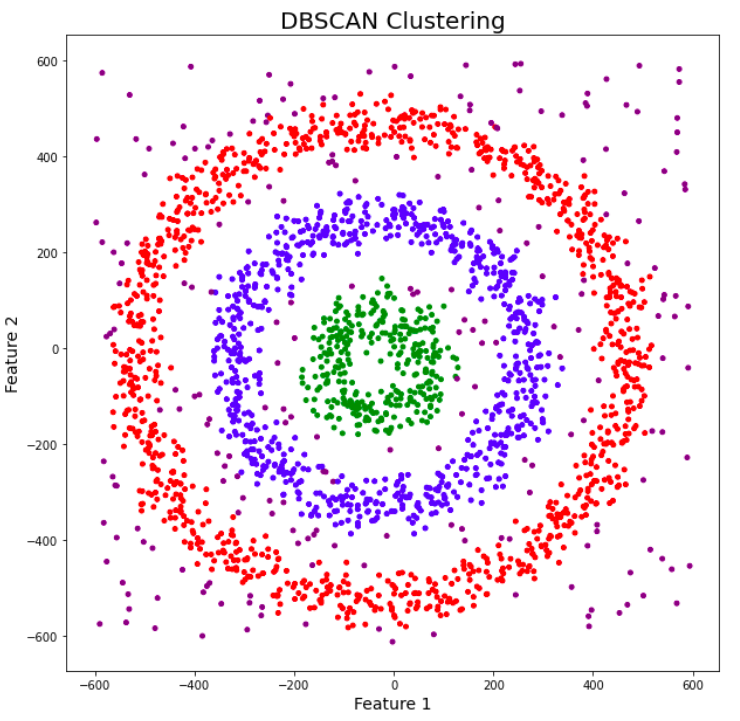
from sklearn.cluster import DBSCAN
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
PCA (Principal Component Analysis)求解協方差矩陣的特徵向量和特徵值
選取前k個最大的特徵值對應的特徵向量作為投影矩陣
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)
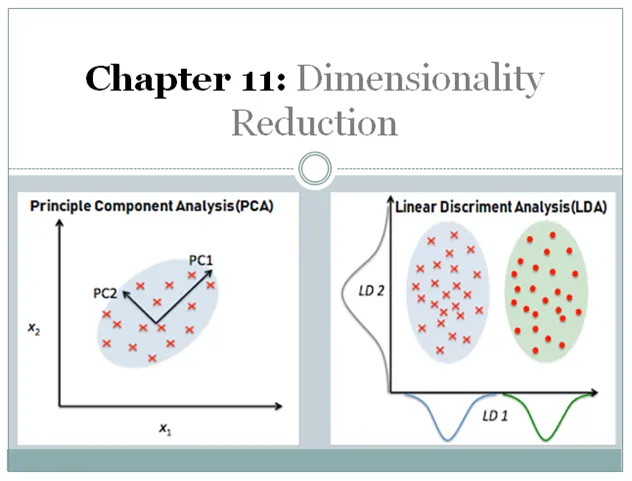
圖片來源:Dimensionality Reduction(PCA and LDA) with Practical Implementation
t-SNE(t-Distributed Stochastic Neighbor Embedding)基於概率分布非線性降維方法,通常可視化高維數據
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=0)
X_embedded = tsne.fit_transform(X)
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# 載入鳶尾花資料集
iris = load_iris()
X = iris.data
y = iris.target
# K-means聚類
kmeans = KMeans(n_clusters=3, random_state=0).fit(X)
print(kmeans.labels_)
# PCA降維
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)


 iThome鐵人賽
iThome鐵人賽